《星际2》,人类首战告负。
2016年3月DeepMind团队的AlphaGo击败世界围棋顶级棋手李世石,但在AlphaGo还名不见经传时,它首先是与职业棋手樊麾较量取得胜利,而如今该团队设计的新的AlphaStar同样击败了星际2的职业选手TLO和MaNa。
TLO是一位德国职业星际2选手,原名Dario Wünsch,1990年7月13日出生。现在效力于职业游戏战队Liquid。根据官方公布的数据,TLO在2018 WCS Circuit排名:44。

(德国职业星际2选手TLO)
MaNa是一位出生于波兰的职业星际2选手,原名Grzegorz Komincz,1993年12月14日出生,目前也效力于Liquid。MaNa去年获得WCS Austin的第二名。根据官方公布的数据,他在2018 WCS Circuit排名:13。

(波兰的职业星际2选手MaNa)
1月25日,DeepMind 的AI AlphaStar 首次亮相。DeepMind 公布了其录制的 AI 在《星际争霸 2》中与2位职业选手的比赛过程:AlphaStar 分别以5:0的成绩战胜了两位职业选手 TLO 和 MaNa 。

最后直播的一场比赛中,DeepMind限制了AlphaStar的游戏视角,并在没有测试的前提下与MANA进行比赛,让人类终于赢了一场。
如何打造 AlphaStar
对于如何训练AlphaStar,DeepMind 科学家 Oriol Vinyals、David Silver 表示,首先是模仿学习,团队从许多选手那里获得了很多比赛回放资料,并试图让 AI 通过观察一个人所处的环境,尽可能地模仿某个特定的动作,从而理解星际争霸的基本知识。这其中所使用到的训练资料不但包括专业选手,也包括业余选手。这是 AlphaStar 成型的第一步。
AlphaStar学会打星际,全靠深度神经网络,这个网络从原始游戏界面接收数据 (输入) ,然后输出一系列指令,组成游戏中的某一个动作。
再说得具体一些,神经网络结构对星际里的那些单位,应用一个Transformer,再结合一个深度LSTM核心,一个自动回归策略 (在头部) ,以及一个集中值基线 (Centralised Value Baseline)。
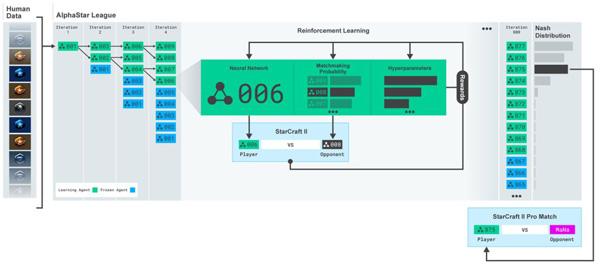
团队会使用一个称为“Alpha League”的方法。在这个方法中,Alpha League 的第一个竞争对手就是从人类数据中训练出来的神经网络,然后进行一次又一次的迭代,产生新的 agent 和分支,用以壮大“Alpha League”。
然后,这些 agent 通过强化学习过程与“Alpha League”中的其他竞争对手进行比赛,以便尽可能有效地击败所有这些不同的策略,此外,还可以通过调整它们的个人学习目标来鼓励竞争对手朝着特定方式演进,比如说旨在获得特定的奖励。
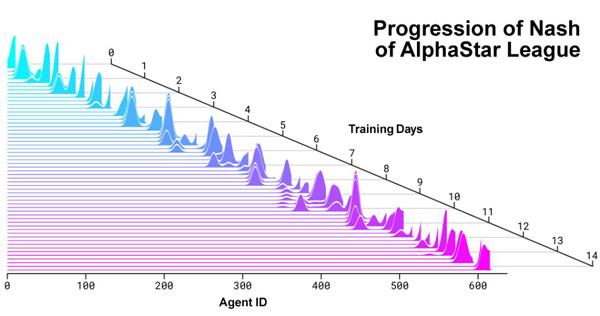
最后,团队在“Alpha League”中选择了最不容易被利用的 agent,称之为“the nash of League”。
AI打星际2意味着什么
早在2003年人类就开始尝试用AI解决即时战略(RTS)游戏问题。那时候AI还连围棋问题还没有解决,而RTS比围棋还要复杂。
直到2016年,“阿尔法狗”打败了李世石。DeepMind在解决围棋问题后,很快把目光转向了《星际2》。
与国际象棋或围棋不同,星际玩家面对的是“不完美信息博弈”。
在玩家做决策之前,围棋棋盘上所有的信息都能直接看到。而游戏中的“战争迷雾”却让你无法看到对方的操作、阴影中有哪些单位。
这意味着玩家的规划、决策、行动,要一段时间后才能看到结果。这类问题在现实世界中具有重要意义。
为了获胜,玩家必须在宏观战略和微观操作之间取得平衡。
平衡短期和长期目标并适应意外情况的需要,对脆弱和缺乏灵活性的系统构成了巨大挑战。
掌握这个问题需要在几个AI研究挑战中取得突破,包括:
・ 博弈论:星际争霸没有单一的最佳策略。因此,AI训练过程需要不断探索和拓展战略知识的前沿。
・ 不完美信息:不像象棋或围棋那样,棋手什么都看得到,关键信息对星际玩家来说是隐藏的,必须通过“侦察”来主动发现。
・ 长期规划:像许多现实世界中的问题一样,因果关系不是立竿见影的。游戏可能需要一个小时才能结束,这意味着游戏早期采取的行动可能在很长一段时间内都不会有回报。
・ 实时:不同于传统的棋类游戏,星际争霸玩家必须随着游戏时间的推移不断地执行动作。
・ 更大的操作空间:必须实时控制数百个不同的单元和建筑物,从而形成可能的组合空间。此外,操作是分层的,可以修改和扩充。
为了进一步探索这些问题,DeepMind与暴雪2017年合作发布了一套名为PySC2的开源工具,在此基础上,结合工程和算法突破,才有了现在的AlphaStar。
除了DeepMind以外,其他公司和高校去年也积极备战:
・ 4月,南京大学的俞扬团队,研究了《星际2》的分层强化学习方法,在对战最高等级的无作弊电脑情况下,胜率超过93%。
・ 9月,腾讯AI Lab发布论文称,他们构建的AI首次在完整的虫族VS虫族比赛中击败了星际2的内置机器人Bot。
・ 11月,加州大学伯克利分校在星际2中使用了一种新型模块化AI架构,用虫族对抗电脑难度5级的虫族时,分别达到 94%(有战争迷雾)和 87%(无战争迷雾)的胜率。
DeepMind CEO哈萨比斯在赛后说,虽然星际争霸“只是”一个非常复杂的游戏,但他对AlphaStar背后的技术更感兴趣。其中包含的超长序列的预测,未来可以用在天气预测和气候建模中。
内容根据微信公众号量子位、 钛媒体APP、 36氪等资料综合整理
中国
青年报
中青
看点
中青
校园
青创
头条
京ICP备13016345号-8 |  京公网安备 11010102004843号|24小时违法和不良信息举报电话:010-64098588
京公网安备 11010102004843号|24小时违法和不良信息举报电话:010-64098588
互联网新闻信息服务许可证10120170007号 |增值电信业务经营许可证A2.B1-20232628/京B2-20224905号|信息网络传播视听节目许可证0105108号
共青团中央主办 中国青年报主管 中青网新媒体科技(北京)有限公司版权所有















